이전 두 장에서는 R을 이용해 추천 시스템을 구축하고 테스트하고 최적화하는 방법을 알아봤다. 각 장에는 다양한 예제들이 있었지만, 모두 R 패키지에서 제공하는 데이터 세트를 이용했다. 이 데이터들은 모두 구조화된 상태로, 바로 적용 가능하도록 준비돼 있었다. 하지만 우리가 다루는 현실 세계의 데이터들은 이처럼 구조화되고 정제돼 있지 않을 가능성이 높으므로 데이터의 준비 고정에 많은 시간고 노력이 든다.
또한 지금까지 다룬 예제들은 평점(Rating) 데이터만을 이용했다. 그러나 현실 세계에서는 대부분의 경우 고객 정보와 아이템에 대한 설명과 같은 추가적인 정보를 가지고 있다.우수한 성능을 가진 추천 시스템을 만들기 위해서는 이처럼 관련된 모든 정보들을 조합해야 한다.
이 장에서는 원시 데이터(Raw Data)를 이용해 추천 시스템을 만들고 최적화하는 좀 더 실용적인 예제를 다룬다. 이 장에서 다루는 내용은 다음과 같다.
- 추천 시스템을 만들기 위한 데이터 준비
- 시각화 기법을 통한 데이터 탐색
- 추천 모델 선택 및 구축
- 매개변수 조정을 통한 추천 모델의 성능 최적화
이제부터 위와 같은 과정을 거쳐 추천 시스템을 만들어볼 것이다.
데이터 준비하기
이번 절에서는 추천 모델을 만들기 위해 원시 데이터를 필요한 입력 데이터의 형태로 가공하는 과정을 설명한다.
데이터에 대한 설명
이 데이터 세트(https://kdd.ics.uci.edu/databases/msweb/msweb.html)는 마이크로소프트 웹사이트를 방문한 사용자들이 특정한 일주일 동안 웹 페이지의 어느 영역(아이템)을 조회했는지를 기록한 자료다.
데이터에 포함된 5,000명의 사용자들은 10,001에서 15,000 사이의 숫자로 표기돼 있으며, 298개의 아이템들은 1,000에서 1,297 사이의 숫자로 표기돼 있다.
데이터 세트는 구조화되지 않은 텍스트 파일의 형태로, 각 행은 두 개에서 여섯 개까지의 열을 갖고 있다. 첫 번째 열에는 행에 포함된 정보를 설명하는 대표 코득 입력돼 있으며, 다음과 같은 세 가지 주요 코드가 있다.
- A(Atrivute) : 웹사이트 영역(아이템)의 영역 번호와 해당 영역에 대한 설명을 포함한다.
- C(Case) : 사용자의 고유 번호를 포함한다.
- V(Vote) : 상위 C 열에 포함된 사용자가 조회한, 웹 사이트 영역 번호를 포함한다.
사용자 고유 번호가 포함된 C 행 밑으로 해당 사용자가 조회한 웹사이트 영역 번호를 포함하는 V 행이 이어진다. 사용자 고유 번호는 중복 없이 한 번씩만 들어가 있다.
우리의 목표는 사용자들이 아직 조회하지 않은 웹사이트의 다른 영역을 조회하도록 추천하는 것이다.
데이터 불러오기
이번 절에서는 데이터를 불러오는 방법을 설명한다. 먼저 사용할 R 패키지를 불러온다.
library(data.table)
library(ggplot2)
library(recommenderlab)
library(countrycode)앞에서 불러온 패키지는 다음과 같은 특징이 있다.
- data.table : 데이터를 다루기 위한 함수를 제공한다.
- ggplot2 : 도표를 그리는 함수를 제공한다.
- recommenderlab : 추천 시스템을 만드는 함수를 제공한다.
- countrycode : 국가 이름 등의 데이터를 제공한다.
다음으로 테이블을 메모리에 할당해본다. 만약 텍스트 파일이 이미 작업 폴더에 있다면, 변수 이름을 정의하고 불러오는 것으로 충분하다. 그렇지 않으면 텍스트 파일이 위치한 전체 경로를 정의해야 한다.
file_in <- "anonymous-msweb.test"행에 각기 다른 개수의 열이 있다. 즉 데이터가 구조호돼 있지 않다. 그러나 최대 여섯개의 열이 있으므로 read.csv 함수를 이용해서 테이블 형태로 불러올 수 있다. 여섯개 미만의 열이 있는 행은 빈 값들을 갖게 된다.
table_in <- read.csv(file_in, header = FALSE)
head(table_in)
V1 V2 V3 V4 V5 V6
1 I 4 www.microsoft.com created by getlog.pl
2 T 1 VRoot 0 0 VRoot
3 N 0 0
4 N 1 1
5 T 2 Hide1 0 0 Hide
6 N 0 0 첫 번째 열고 두 번째 열에는 사용자의 고유 번호와 그들이 조회한 웹 페이지 영역 번호가 들어있다.
앞의 두 개 열 이외에 나머지 열은 제거할 수 있다.
table_user <- table_in[, 1:2]데이터를 좀 더 편하게 다루기 위해 다음 명령어를 사용해 데이터 타입을 data.table로 변환할 수 있다.
table_users <- data.table(table_users)분리한 열들은 다음과 같다.
- category : 행의 내용을 지정하는 구분 코드로 주로 C와 V라는 값이 포함돼 있다. C는 사용자 고유 번호가 포함된 행을 의미하며, V는 해당 사용자가 조회한 웹사이트의 영역 번호가 포함돼 있음을 의미한다.
- value : 사용자 고유 번호와 웹사이트 영역 번호가 입력돼 있다.
열에 이름을 지정하고, 사용자 또는 아이템에 대한 정보를 포함하는 행만 분리할 수 있다.
setnames(table_users, 1:2, c("category", "value"))
table_users <- table_users[category %in% c("C", "V")]
head(table_users)
category value
1: C 10001
2: V 1038
3: V 1026
4: V 1034
5: C 10002
6: V 1008
이렇게 만든 table_users 객체의 데이터는 구조화돼 있다. 이와 같이 데이터 구조화는 추천 시스템을 만들기 위해 필요한 평점 매트릭스를 정의하는 첫걸음이다.
평점 매트릭스 정의하기
우리의 목표는 각 사용자별로 각 웹사이트 영역에 대한 조회 여부를 나타내는 테이블을 정의하는 것ㅇ디ㅏ. 현재 table_users 객체에는 각 사용자의 고유 번호와 조회한 영역 번호가 하나의 열에, 다른 행으로 입력돼 잇다. category 열에 c로 입력된 행의 value 값으 ㄴ사용자의 고유 번호를 의미하며, 뒤다르는 category 값 V 행의 value 값은 앞선 사용자가 조회한 웹사이트의 영역 번호를 의미한다.
이제 다음 과정을 통해 평점 매트릭스를 정의할 수 있다.
- 사용자별 조회 정보를 그룹화할 수 잇는 번호를 부여한다.
- long 포맷의 데이터로 테이블을 변환한다.
- wide 포맷의 데이터로 테이블을 변환한다.
- 데이터 타입을 이진 평점 매트릭스(binaryRatingMatrix)로 변환한다.
평점 매트릭스를 정의하는 첫 단계는 사용자별 조회 데이터를 그룹화하는 번호를 부여하는 것이다. 이를 위해 chunk_user 라는 열을 추가해, 사용자가 바뀔 때마다 번호를 1씩 증가시켜 부여한다. 다음 코드의 category == "C" 라는 구문은 category의 코드 값이 C로 입력된 행을 기점으로 숫자를 1씩 증가시킨다는 의미다. 즉, 새로운 사용자가 나타나는 행마다 cumsum 함수를 이용해 chunk_user의 번호를 1 씩 증가시킨다.
table_users[, chunk_user := cumsum(category == "C")]
head(table_users)
category value chunk_user
1: C 10001 1
2: V 1038 1
3: V 1026 1
4: V 1034 1
5: C 10002 2
6: V 1008 2다음 단계는 사용자가 조회한 영역 번호를 별도의 열로 갖는 테이블을 정의하는 것이다. 이를 위해 value 열에 같이 들어가 있는 사용자 고유 번호와 영역 번호를 분리해 각각의 열로 만든다. 이렇게 만든 새로운 테이블은 long 포맷의 데이터라고 일컬어지기 대문에 table_long이라는 이름의 변수에 넣는다.
table_long <- table_users[, list(user = value[1], item = value[-1]), by = "chunk_user"]
head(table_long)
chunk_user user item
1: 1 10001 1038
2: 1 10001 1026
3: 1 10001 1034
4: 2 10002 1008
5: 2 10002 1056
6: 2 10002 1032이제 사용자별로 행이 구분되고 웹사이트의 영역 번호가 열로 이뤄진 테이블을 정의할 수 잇다. 사용자가 해당 웹사이트 영역을 조회한 경우 1, 조회하지 않은 경우 0의 값을 부여한다. 이는 reshape 함수를 사용해 만들 수 있다. reshape 함수의 입력 매개변수는 다음과 같다.
- data : 입력할 데이터를 표시한다. long 포맷 형태로 가공된 데이터를 입력받는다.
- direction : 데이터를 어떤 방법으로 재구성할 것인지 지정한다(예 : long 포맷에서 wide 포맷으로).
- idvar : 그룹을 식별하는 매개변수먀, 이번 예제의 경우 user열에 해당한다.
- timevar : wide 포맷의 열로 피봇시킬 변수를 지정하는 매개변수며, 이 경우 item열에 해당한다.
- v.name : 셀에 지정할 값이며 이번 예제의 경우 사용자가 조회한 영역 번호에 공통적으로 숫자 1을 부여한다. 조회하지 않은 영역 번호의 value 값에는 자동으로 NA 값이 입력된다.
value 값을 1로 부여하고, reshape 함수를 사용해 wide 포맷 형태로 재구성한다.변환한 데이터를 table_wide 변수에 저장한다.
table_long[, value := 1]
table_wide <- reshape(data = table_long,
direction = "wide",
idvar = "user",
timevar = "item",
v.names = "value")
head(table_wide[, 1:5, with = FALSE])
chunk_user user value.1038 value.1026 value.1034
1: 1 10001 1 1 1
2: 2 10002 NA NA NA
3: 3 10003 1 1 NA
4: 4 10004 NA NA NA
5: 5 10005 1 1 1
6: 6 10006 NA NA 1다음으로 평점 매트릭스를 만들기 위해서는 value 값이 포함된 열만 필요하다. 사용자 고유 번호는 추후 생성할 매트릭스의 행 이름으로 사용할 것이므로, vector_users라는 변수에 따로 저장해둔다.
vector_users <- table_wide[, user]
table_wide[, user := NULL]
table_wide[, chunk_user := NULL]table_wide의 열 이름에서 'value.'라는 접두사를 제거해 웹 페이지의 영역 번호와 열 이름을 일치시킨다. 이를 위해 substring 함수를 사용한다.
setnames(x = table_wide,
old = names(table_wide),
new = substring(names(table_wide), 7))여기까지 만든 평점 매트릭스는 recommenderlab의 객체에 저장해야 한다. 이를 위해 table_wide를 matrix 형태로 변환한다. 그리고 변환한 matrix의 행 이름에 vector_users에 담아둔 사용자 고유 번호를 붙인다.
matrix_wide <- as.matrix(table_wide)
rownames(matrix_wide) <- vector_users
head(matrix_wide[, 1:6])
1038 1026 1034 1008 1056 1032
10001 1 1 1 NA NA NA
10002 NA NA NA 1 1 1
10003 1 1 NA NA NA NA
10004 NA NA NA NA NA NA
10005 1 1 1 1 NA NA
10006 NA NA 1 NA NA NA마지막 단계는 matrix_wide 매트릭스를 다음과 같이 as 함수를 사용해서 binaryRatingmatrix로 변환하는 것이다.
matrix_wide[is.na(matrix_wide)] <- 0
ratings_matrix <- as(matrix_wide, "binaryRatingMatrix")
ratings_matrix
5000 x 236 rating matrix of class ‘binaryRatingMatrix’ with 15191 ratings.그림을 통해 매트릭스를 살펴보자.
image(ratings_matrix[1:50, 1:50], main = "Binary rating matrix")다음 그림은 이진 평점 매트릭스의 패턴을 보여준다.
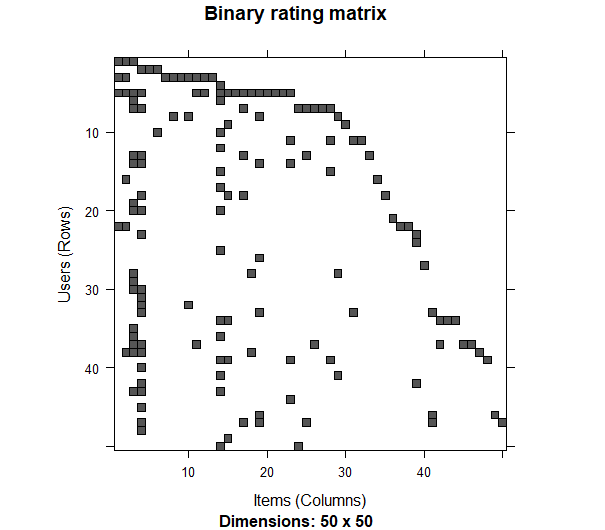
예상대로 매트릭스는 희소(sparse)하다. 우리는 또한 웹사이트 영역에 대한 사용자들의 조회 수 분포를 시각화해볼 수 있다.
n_users <- colCounts(ratings_matrix)
qplot(n_users) + stat_bin(binwidth = 100) +
ggtitle("Distribution of the number of users")다음 그림은 웹사이트 영역에 대한 사용자의 조회 수 분포를 보여준다.

여기에는 일부 아웃라이어(Outlier), 즉 극단적으로 많은 사용자가 조회한 웹사이트 영역이 있음을 알 수 있다. 그 영역들을 제외한 분포를 시각화해본다.
qplot(n_users[n_users < 100]) + stat_bin(binwidth = 10) +
ggtitle("Distribution of the number of users")다음 그림은 아웃라이어에 해당하는 영역을 제외한 영역들에 대한 사용자의 조회 수 분포다.

여기서는 다시 극소수의 사용자만 조회한 영역들이 있음을 볼 수 있다. 이렇게 소수의 사용자만 조회한 웹사이트 영역을 다른 사용자들에게 추천해주고 싶지는 않으므로, 영역에 대한 사용자의 최소 조회 수 기준을 정의해 추천 항목에서 제거한다. 예를 들면 5회 이상 조회된 웹사이트 영역들만 추천 대상 아이템으로 설정한다.
ratings_matrix <- ratings_matrix[, colCounts(ratings_matrix) >=5]
ratings_matrix
5000 x 166 rating matrix of class ‘binaryRatingMatrix’ with 15043 ratings.이제 최초의 236개 아이템에서 166개 아이템으로 줄어들었다. 모든 사용자에게 아이템을 추천하고 싶지만, 방금 전에 제거한 웹사이트 영역만 조회한 사용자가 잇을 수 있다. 이를 확인해본다.
sum(rowCounts(ratings_matrix) == 0)
[1] 15앞선 작업에 다라 15명 사용자의 웹사이트 조회 기록이 사라졌다. 즉, 15명은 제거한 웹사이트 영역만 조회했다. 이러한 사용자들 역시 추천을 위한 대상에서 제거한다. 또한 몇 개 안되는 웹사이트 영역만 조회한 사용자에게는 다른 영역을 추천해주기가 어렵다. 따라서 적어도 다섯 개 이상의 영역을 조회한 사용자에게만 아이템을 추천해주기로 한다.
ratings_matrix <- ratings_matrix[rowCounts(ratings_matrix) >= 5, ]
ratings_matrix
959 x 166 rating matrix of class ‘binaryRatingMatrix’ with 6816 ratings.'R > R로 만드는 추천 시스템' 카테고리의 다른 글
| 사례 연구 : 나만의 추천 시스템 만들기 - 03 (0) | 2020.04.01 |
|---|---|
| 사례 연구 : 나만의 추천 시스템 만들기 - 02 (0) | 2020.03.31 |
| 추천 시스템의 평가 - 04 (0) | 2020.03.29 |
| 추천 시스템의 평가 - 03 (0) | 2020.03.24 |
| 추천 시스템의 평가 - 02 (0) | 2020.03.24 |



